
Up: abstracts
Previous: Abstracts E-N
Noboru Ohsumi, Institute of Statistical Mathematics,
``Memories of Chikio Hayashi and His Great Achievement''
Abs:
TBA
Michael Ong, Illinois Institute of Technology, ``The Use and
Ab-Use of Financial Data''
Abs: TBA
C. Osswald and F. Brucker, GET-ENST Bretagne,
``Circular Dissimilarities and Hypercycles''
Abs:
In this talk, we present a generalization of Robinsonian
dissimilarities called circular dissimilarities. As Robinsonian
dissimilarities are the dissimilarities whose clusters (the maximal
cliques of its threshold graphs) form an interval hypergraph, clusters
of a circular dissimilarities form a hypercycle - a hypergraph
compatible with a cycle (Quilliot, 1984).
We introduce five-points conditions on a linear order that define
circular dissimilarities. These dissimilarities form a submodel of the
model introduced by Hubert, Arabie and Meulman (1998) who have used
circular orders to extend the inequalities defining the Robinsonian
dissimilarities.
Moreover, we propose an algorithm to recognize hypercycles in
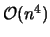 operations, leading to the recognition of circular
dissimilarities in
operations, leading to the recognition of circular
dissimilarities in
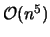 operations.
Barthélemy and Brucker (2001) have shown that approximating a given
dissimilarity by a circular dissimilarity is NP-hard. Finally, we
propose a heuristic to produce a circular dissimilarity compatible
with a given order in
operations, and illustrate
our model with a few examples.
operations.
Barthélemy and Brucker (2001) have shown that approximating a given
dissimilarity by a circular dissimilarity is NP-hard. Finally, we
propose a heuristic to produce a circular dissimilarity compatible
with a given order in
operations, and illustrate
our model with a few examples.
Kutluhan Kemal Pak and Edwin Diday, Univeristé Paris IX-Dauphine,
``Construction of Spatial Hierarchies''
Abs:
The goal of this work is to extend the traditional hierarchical
clustering to spatial hierarchies based on a grid. First we show that
a spatial hierarchy induces a kind of dissimilarity called Yadidean
defined in Diday (IFCS'2004). Second, we present an ascending
algorithm starting from a symbolic data file (which contains as a
special case, the standard data). This algorithm gives as output, a
spatial hierarchy where each cluster is a convex of the grid and is
modelled by a symbolic object. Finally we discuss about the properties
of the constructed spatial hierarchy, its quality, and the
compatibility between the Yadidean dissimilarity and the grid. The
program written in C++, has a graphic tool which is carried out using
the OpenGL library. We give several tools for the interpretation. The
resulting spatial hierarchy is a 3D graphic that can be rotated and
zoomed. Each cluster of the hierarchy has its own colour depending on
its height and the individuals who belong to the grid can be
interactively interpreted in several ways.
Barbara Japelj Pavesic, Educational Research
Institute, Simona KorenjakCerne, University of Ljubljana, and
Vladimir Batagelj, University of Ljubljana,
``An Application of Symbolic Clustering Methods on the TIMSS Dataset''
Abs:
Is teaching mathematics culturally independent? Trends in Interna
tional Mathematics and Science Study, TIMSS, collected information
from students
and teachers from different countries all over the world to describe
differences in
teaching mathematics. In the paper, the teachers' and students'
datasets, collected
in TIMSS 1999 from 37 participating countries, are combined into a
single dataset.
In this dataset, teachers are described as symbolic objects, including
the distributions of their students' answers about the activities during
mathematics lessons.
Based on this descriptions the adapted leaders method was used to
partition all
teachers into clusters. The connections between the clusters are
presented with
dendrogram, based on the adapted Ward's method. The analysis of characteristic
properties of clusters' leaders provide some answers to the initial question.
Jean-Yves Pirçon and Jean-Paul Rasson, University of
Namur, ``The Last Step of a New
Divisive Monothetic Clustering Method: The Gluing-Back Criterion''
Abs:
Pirçon and Rasson (2003) propose a divisive monothetic clustering
method. In that work, the selection of relevant variables is
performed simultaneously with the formation of clusters. The
method treats only one variable at each stage; a single variable is chosen
to split a cluster into two sub-clusters. Then the sub-clusters are
successively split until a stopping criterion is satisfied.
The original splitting criterion is the solution of a
maximum likelihood problem conditional on the fact that data are
generated by a nonhomogeneous Poisson process on two disjoint
intervals. The criterion splits at the place of the maximum
integrated intensity between two consecutive points.
This paper extends Pirçon and Rasson (2003) by developing a
``gluing-back'' criterion. The previous work explained the new method
for combining trees and nonhomogeneous Poisson processes and the
splitting criterion.
It was shown that
the maximum likelihood criterion reduces to minimization of the integrated
intensity on the domain containing all of the points. This method of
clustering is indexed, divisive and monothetic hierarchical, but its
performance can be improved through a gluing-back criterion.
That criterion is developed in this paper, after a brief review of the
main ideas.
Jennifer Pittman and Mike West, Duke University,
``Issues in Bayesian Tree Modeling of Clinical and Gene Expression Data''
Abs:
Recent studies have demonstrated the usefulness of gene expression information
in the search for improved diagnostic and prognostic tools as a part of overall
cancer treatment. For example, gene expression profiles have been used to more
accurately predict patient outcome in comparison to clinical indicators
while the clustering of breast carcinomas by gene
expression patterns has also been shown to be highly correlated with
both overall and relapse-free survival.
We have developed an approach to the analysis and modeling of clinical
and gene expression data based on Bayesian tree models. Our current aim is to
generate classification tree models which can exploit such data
to characterize clinical states and predict cancer-related outcomes for
patients of interest. Through cross-validation this Bayesian tree approach
provides an honest measure of the uncertainty or accuracy of these predictions.
Providing a measure of accuracy is critical, as it provides information
regarding the quality or value of such predictions. The development and
generation of our models involves statistical issues such as the specification
a Bayesian model for the data, the choice of a measure to determine tree
growth, and the selection of a method for searching through the tree model
space. This talk will focus on a discussion of these issues in the context of
Bayesian predictive classification tree analyses. Applications of
our models to the predictive analysis of outcomes in breast cancer and ovarian
cancer will be presented.
Margaret Polinkovsky, Duke University, ``Analysis of Key Comparisons''
Abs: TBA
Robert C. Powers, University of Louisville,
``Consensus Functions on Hierarchies that Satisfy
Independence and Pareto''
Abs:
Let 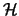 be the set of all hierarchies on a finite set
be the set of all hierarchies on a finite set 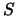 . A
consensus function on
is a map
. A
consensus function on
is a map
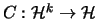 where
where 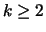 . A consensus function
. A consensus function 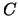 satisfies independence
if, whenever two profiles agree when restricted to a subset
satisfies independence
if, whenever two profiles agree when restricted to a subset 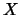 of , then
the corresponding consensus outputs agree when restricted to .
If preserves
unanimity with respect to clusters, then is said to satisfy the
Pareto condition.
Barthélemey et al. (1991) gave an example of a consensus function
on such
that satisfies independence, Pareto, and is not a
dictatorship. The surprising
nature of this example leads to the following problem. Give a complete
description
of all the consensus functions on that satisfy
independence and Pareto. I will
present some recent work that provides a partial solution to this
problem.
of , then
the corresponding consensus outputs agree when restricted to .
If preserves
unanimity with respect to clusters, then is said to satisfy the
Pareto condition.
Barthélemey et al. (1991) gave an example of a consensus function
on such
that satisfies independence, Pareto, and is not a
dictatorship. The surprising
nature of this example leads to the following problem. Give a complete
description
of all the consensus functions on that satisfy
independence and Pareto. I will
present some recent work that provides a partial solution to this
problem.
Carey Priebe, Johns Hopkins University, ``Applying the Class Cover Catch
Digraph Classifier''
Abs:
We describe an extension of the Class Cover Catch Digraph (CCCD) classifier,
specifically designed for detection problems--two-class
classification problems in which
the natural priors on the classes are severely skewed.
The emphasis of our approach is on
computationally efficient classification for real-time applications.
Our principal contribution is a boosted tree classifier
built upon the CCCD structure.
This classifier achieves performance comparable to that of the original
CCCD classifier, but at drastically reduced computational expense.
An analysis of classification performance and computational cost is
performed using data from a face detection application.
Comparisons are provided with Support Vector Machines (SVMs).
These comparisons show that while some SVMs may achieve superior
classification performance, their computational burden is so high as
to make them unusable in real-time applications. On the other hand,
our proposed classifiers combine high detection performance with
extremely fast classification.
Sarnath Ramnath, Mynul H. Khan, and Subair Shams, St. Cloud
State University, ``New Approaches
for Sum-of-Distances Clustering''
Abs:
It was shown recently that by employing ideas from
incremental graph connectivity the asymptotic complexity of
sum-of-diameters bipartitioning could be reduced. This article further
exploits this idea to develop simpler algorithms and reports on an
experimental comparison of all algorithms for this problem.
Jim Ramsay, McGill University, ``Modeling the Evolution of
Disease Symptoms with Principal Differential Analysis''
Abs:
This talk describes the application of functional data analysis
techniques to study the course of systemic lupus erythematosus
in a sample of patients. The method models patient histories by
fitting a pair of differential equations to the data. The purpose
is to predict the duration of a flare-up and its speed of onset.
Jean-Paul Rasson and Pascale Lallemand, Facultés
Universitaires Notre-Dame de la Paix,
``Clustering Trees Applied to Symbolic Objects''
Abs:
The present method is a divisive clustering method for symbolic
data. By definition of a divisive clustering method, the algorithm
starts with all objects in one cluster, and splits successively
each cluster into (two) smaller ones until a suitable stopping
rule prevents further divisions. This algorithm proceeds also in a
monothetic way. In other words, the algorithm assumes as input 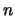 data vectors and proceeds such that each split is carried out by
using only one single variable (which is selected optimally).
The aim of our work is to build a recursive algorithm for sharing
a given population of symbolic objects into classes. The original
contribution of this method lies in the way of splitting a node.
Indeed, the cut will be based on the only assumption that the
distributions of points can be modeled by non-homogeneous Poisson
process where the intensity will be estimated by the kernel
method. The cut will be made in order to maximize the likelihood
function.
data vectors and proceeds such that each split is carried out by
using only one single variable (which is selected optimally).
The aim of our work is to build a recursive algorithm for sharing
a given population of symbolic objects into classes. The original
contribution of this method lies in the way of splitting a node.
Indeed, the cut will be based on the only assumption that the
distributions of points can be modeled by non-homogeneous Poisson
process where the intensity will be estimated by the kernel
method. The cut will be made in order to maximize the likelihood
function.
Jean-Paul Rasson and Laurent Sancinito Spito, University of Namur,
``Partitioning Non-Convex Clusters Using Alpha-Shapes''
Abs:
The aim of our work is to propose a new partitionning method and a new
discriminant rule for the basic space
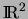 . We introduce the
concept of internally path connected bodies, which allow us to relax
the convexity hypothesis of the hypervolume method (Rasson, Hardy
(1982)). Our wish is to generalize the latter because of its failure
in finding non convex natural classes. We try to build unsupervised
and supervised classification rules and algorithms, based on this new
assumption, with the help of a tool that generalizes the convex hull
of a set of points : the alpha-shape.
The generalization to
. We introduce the
concept of internally path connected bodies, which allow us to relax
the convexity hypothesis of the hypervolume method (Rasson, Hardy
(1982)). Our wish is to generalize the latter because of its failure
in finding non convex natural classes. We try to build unsupervised
and supervised classification rules and algorithms, based on this new
assumption, with the help of a tool that generalizes the convex hull
of a set of points : the alpha-shape.
The generalization to
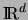 of the hypotheses we make and the tools
we use is straightforward.
of the hypotheses we make and the tools
we use is straightforward.
Gunter Ritter and María Teresa Gallegos,
Universität Passau, ``Clustering of Contaminated and Ambiguous
Data''
Abs:
We present a number of clustering algorithms for
Euclidean data with outliers. Besides outlier treatment by trimming,
as an additional novelty we allow the data to be
ambiguous. This means that each object may be represented by
more than one feature set (variant), only one of which is valid
(the regular variant), (2). In addition to
clustering and outlier removal, the algorithms automatically select
the regular variants of the objects.
The algorithms are based on mixed MAP-ML-criteria, MAP with respect
to variant selection and ML with respect to outlier detection and the
distribution parameters. They are most efficient if the ML-estimator
of these parameters has a simple form. This is the case with various
normal data models. The algorithms have the usual EM flavor and
combine ML clustering with Rousseeuw's minimum covariance determinant
estimator, cf. Pesch (1) and Rousseeuw and Van Driessen (3).
We illustrate the results by simulation studies and applications to
real data sets.
O. Rodríguez, University of Costa Rica, W. Castillo,
University of Costa Rica, E. Diday, University of Paris
IX-Dauphine, and J. González, University of Costa Rica,
``Correspondence Factorial Analysis for Symbolic Multi-Valued
Variables''
Abs:
In this paper a new method and two new algorithms for
Correspondence Factorial Analysis when we have Symbolic
Multi-Valued Variables (CFASym) are proposed. The method is
illustrated with an example, which was built using the module
CFASym in PIMAD-Symbolique, developed by the authors.
Ingo Ruczinski, Johns Hopkins University,
``Improvements for Logic Regression''
Abs:
Logic Regression was recently introduced as a novel regression method
and classification tool. This adaptive methodology is based on new
predictors being generated as Boolean combinations from binary
covariates, and hence models with high order interactions can be
explored. We show some public health related case studies, highlight
the differences to related methodologies such as CART, MARS and Random
Forests, and report some recent improvements in the methodology (such
as measures of variable importance obtained from MCMC based
algorithms) and the software (in particular, the LogicReg R package).
Takahiro Saito, Hosei University, Kenji Nagasaka, Hosei
University, and Tomokazu Takahashi, Aoyamagakuin University,
``Classification Problems for Story Animations''
Abs:
There are two kinds of animations (manga in Japanese), one of which is
animated cartoon and another is animated story (i.e. story with
pictures). We treat animated stories from a single author, Akira Toriyama,
especially his master work ``DRAGON BALL''. From the usages of imitative
words and/or onomatoeic words, we can estimate the produced period and
also who assisted the production.
From the point of copyright, an important issue is how to detect
discriminate the originals and forgery to which we will apply image
processing tool and theory of statistics.
Gilbert Saporta, CNAM Paris, and Cristian Preda,
Université de Lille,
``Clusterwise PLS Regression with Applications to Functional Data''
Abs:
The Partial Least Squares (PLS) approach is used for the
clusterwise linear regression algorithm when the set of predictor
variables forms an 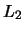 -continuous stochastic process. The number of
clusters is treated as unknown and the convergence
of the clusterwise algorithm is discussed. The approach is
compared with other methods via an application to stock-exchange data.
-continuous stochastic process. The number of
clusters is treated as unknown and the convergence
of the clusterwise algorithm is discussed. The approach is
compared with other methods via an application to stock-exchange data.
Yoshiharu Sato, Hokkaido University,
``Clustering Binary Data Using a Transformation into Directional
Data''
Abs:
Binary data is defined as a set of observed values whose attributes
take the binary value, usually, denoted by 0 or 1. Recently, the
number of attributes and objects become extremely large due to the
progress of the observation and information technology. Then it is
difficult to apply the traditional hierarchical clustering
methods. The feasible methods are limited for the required size of
memory and computational costs. Among the clustering methods, the
k-means method and its modification are frequently used for the large
data set,because of the comparatively low requirements.
In binary data, the most crucial point is a definition of the center
of each cluster. In several papers, the concept of a mode is used, and
the clusters are constructed using parallel algorithm with k-means
method. However, the mode does not determine uniquely. Moreover, in
k-means method, a concept of the within variance of each cluster is
important for the criterion of the clustering. This is closely
connected with the used similarity measure between objects.
Then, for the natural definition of the mean and variance, we
transform the binary data to directional data. Using the concept of
the descriptive measures for the directional data, we extend the
k-means method to binary data.
Jan Schepers and Iven Van Mechelen, University of Leuven,
``Three-Mode Partitioning: An Evaluation of Three Algorithms''
Abs:
In this paper, a simultaneous clustering method for three-way three-
mode data is presented in which the simultaneous clusterings are
restricted to be
partitions of the modes involved in the data. The proposed method is
an extension
of existing simultaneous partitioning methods for two-way two-mode data.
To retrieve the best approximation between the reproduced and the actual three-
dimensional data array, a least squares optimization algorithm is
proposed. In a
simulation study, the overall performance of the algorithm is
discussed and compared to the algorithms recently proposed by Rocci
and Vichi (2003) and Kiers (2004).
and Iven Van Mechelen, University of Leuven,
``Three-Mode Partitioning: An Evaluation of Three Algorithms''
Abs:
In this paper, a simultaneous clustering method for three-way three-
mode data is presented in which the simultaneous clusterings are
restricted to be
partitions of the modes involved in the data. The proposed method is
an extension
of existing simultaneous partitioning methods for two-way two-mode data.
To retrieve the best approximation between the reproduced and the actual three-
dimensional data array, a least squares optimization algorithm is
proposed. In a
simulation study, the overall performance of the algorithm is
discussed and compared to the algorithms recently proposed by Rocci
and Vichi (2003) and Kiers (2004).
Alexander Schliep, Christine Steinhoff, and Alexander
Schoenhuth, Max Planck Institute, ``Inference of Groups
in Gene Expression''
Abs:
The analysis of gene expression time-courses poses many methodological
challenges due to the complexity of the regulatory interactions
producing the observables, their inherent variability and the levels
of noise present even under optimal experimental conditions. On
account of the exploratory nature of the analysis, the questions asked
change frequently, as do prior knowledge and beliefs. Effective
methods should reflect those constraints as well as the interactive
fashion in which the analysis is often performed.
We propose to use a mixture of Hidden Markov Models (HMMs) to find
groups in gene expression time course datasets. Mixtures have a number
of preferable properties. In contrast to clustering, genes do not have
to be partitioned into groups, rather the frequent ambiguity of
function or regulation can be accounted for. They also exhibit a
higher degree of robustness with respect to noise and afford a simple,
entropy-based diagnostic for the level of ambiguity in assignments to
groups given the mixture.
The HMMs used prove effective in modeling the qualitative behavior of
time-course data, as they reflect the time-dependencies of
measurements and allow to capture subtle signals. Lags and the varying
speeds at which the regulatory programs are executed can be handled;
simple variants can be used to deal with further questions of
biological interest.
We present the mixture framework and the estimation method used.
Partially supervised learning makes use of prior information with
respect to membership of genes in the same or distinct groups. A
heuristic for proposing an initial collection of HMMs and modifying
HMMs during the training is discussed, as well as an algorithm to
partition an inferred group into synchronous subgroups. The
performance of our approach is evaluated on artificial and biological
expression data. We conclude with computational aspects of our
implementation of the method.
Teppei Shimamura,  Hiroyuki Minami, and Masahiro Mizuta,
Hokkaido University,
``Nonlinear Regression Modeling Strategy Based on Radial Basis
Function Networks and Absolute Shrinkage''
Abs:
Neural networks provide a
flexible model for extracting usefulinformation from highly
complicated data and give good performance overa wide range of
applications. We consider the construction of nonlinearregression
models with radial basis function networks and maximumpenalized
likelihood methods. In the modeling process, it is crucial howwe
choose the number of the basis functions, the positions of thecentres,
the smoothing parameter, and the regularization parameter. Ifcare is
taken not to choose these parameters, the estimated model oftengives
poor generalization performance.We propose a new regression modeling
strategy based on radial basisfunction networks; choosing as centres
the parameters resulting from anormal mixture model of the underlying
conditional distribution
Hiroyuki Minami, and Masahiro Mizuta,
Hokkaido University,
``Nonlinear Regression Modeling Strategy Based on Radial Basis
Function Networks and Absolute Shrinkage''
Abs:
Neural networks provide a
flexible model for extracting usefulinformation from highly
complicated data and give good performance overa wide range of
applications. We consider the construction of nonlinearregression
models with radial basis function networks and maximumpenalized
likelihood methods. In the modeling process, it is crucial howwe
choose the number of the basis functions, the positions of thecentres,
the smoothing parameter, and the regularization parameter. Ifcare is
taken not to choose these parameters, the estimated model oftengives
poor generalization performance.We propose a new regression modeling
strategy based on radial basisfunction networks; choosing as centres
the parameters resulting from anormal mixture model of the underlying
conditional distribution 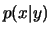 ,and estimating the weights by
maximum penalized log-likelihood withLasso penalty. Furthermore, we
give an information criteria for modelevaluation and apply it to
choose the optimal smoothing paremeter andregularization parameter. We
investigate the performance of the proposedprocedure and compare it
with traditional methods through simulations.The results show the
proposed model performs well and has someadvantages over traditional
methods.
,and estimating the weights by
maximum penalized log-likelihood withLasso penalty. Furthermore, we
give an information criteria for modelevaluation and apply it to
choose the optimal smoothing paremeter andregularization parameter. We
investigate the performance of the proposedprocedure and compare it
with traditional methods through simulations.The results show the
proposed model performs well and has someadvantages over traditional
methods.
Ahu Sieg, Bamshad Mobasher, and Robin Burke, DePaul
University,
``Inferring User's Information Context from User Profiles and Concept
Hierarchies''
Abs:
The critical elements that make up a user's
information context include the user profiles that reveal long-term
interests and trends, the short-term information need as might be
expressed in a query, and the semantic knowledge about the domain
being investigated. The next generation of intelligent information
agents, that can seamlessly integrate these elements into a single
framework, are enabled to effectively locate and provide the most
appropriate results for users' information needs. In this paper we
present one such framework for contextualized information access. We
model the problem in the context of our client-side Web agent ARCH
(Adaptive Retrieval based on Concept Hierarchies). In ARCH, the user
profiles are generated using an unsupervised document clustering
technique. These profiles, in turn, are used to automatically learn
the semantic context of user's information need from a
domain-specific concept hierarchy. Our experimental results show
that implicit measures of user interests, combined with the semantic
knowledge embedded in a concept hierarchy, can be used effectively
to infer the user context and improve the results of information
retrieval.
Age Smilde, University of Amsterdam and TNO Nutrition and Food
Research, Jeroen Jansen, Huub C. J. Hoefsloot, Jan van der Greef, and
Marieke E. Timmerman, ``Multiset Methods for Longitudinal
Metabolomics Data''
Abs:
Metabolomics is a technique that enables quantification and
qualitative analysis of metabolites in biological fluids. There is an
increasing awareness in the biology community that time-resolved
metabolomics measurements contain important information regarding
biological organisms. This is, obviously, related to the dynamic
nature of organisms resulting in biorhythms. Such biorhythms can be
disturbed by external causes (e.g. drug intake, food intake) or
internal causes (e.g. developing diseases). Such disturbances affect
the metabolism of organisms and are expected to show up in properly
measured longitudinal metabolomics data (e.g. in the urine or blood of
the organism).
Longitudinal metabolomics analysis can serve several goals. In
normality studies, the goal is to establish biorhythms under
homeostasis which serve as a reference point to detect future
deviating dynamic behavior. Another goal is to detect early biomarkers
for developing diseases; this calls for models based upon which
biomarker selection can take place. Yet another goal is to model the
dynamic response of an organism to external stress which gives insight
in the way such an external stress influences the system. All these
goals require a different data analysis method. The type of method
depends also on the set-up of the metabolomics data set.
An overview is given of different longitudinal modeling
strategies for metabolomics data. These methods are based on three-way
analysis and (multilevel) simultaneous component analysis. Examples
will be given using i) a longitudinal normality study of monkey urine
and ii) a longitudinal metabolomic diabetes II study of blood
serum. The strengths and limitations of the methods will be
illustrated with these example studies.
Mike Steel, University of Canterbury, New Zealand,
``Phylogenetic Closure Operations and Homoplasy-Free Evolution''
Abs:
Phylogenetic closure operations on partial splits and quartet
trees turn out to be both mathematically interesting and
computationally useful.
Although these operations were defined two decades ago, until recently little
had been established concerning their properties.
Here we present some further
new results and links between these closure operations, and show how
they can be applied in phylogeny reconstruction and enumeration.
Using the operations we study how effectively one may be able to
reconstruct phylogenies from evolved multi-state characters that take
values in a
large state space (such as may arise with certain genomic data).
Russell Steele, McGill University, and Luis Garcia, Virginia
Tech University, ``Algebraic Geometry and Model Selection''
Abs:
Recent advancements in the machine learning community have been made in
the application of algebraic geometry to Bayesian model selection for
neural networks. Rusakov and Geiger (2003), using results from Watanabe
(2001), present a new asymptotic approximation to the integrated
likelihood for Naive Bayes networks. The key to the approximation is an
attempt to correct the standard dimensionality penalty for the BIC to
reflect the ``true'' effective dimensionality of the model. However, only
limited work has been done to interpret these results with respect to
current work on effective dimensionality in Bayesian research,
particularly, in light of the currently widespread use of the DIC
(Spiegelhalter, et al., 2002). In this talk, the speaker presents the
basic idea behind the Rusakov/Geiger approximation, compares their
approximation to the actual integrated likelihood, and links these
results to what the DIC presumably is trying to estimate. The speaker
will conclude with discussion of how these results for Naive Bayes
networks may possibly be used to improve integrated likelihood
calculations for other statistical models.
Douglas Steinley, University of Illinois at Urbana-Champaign,
``Standardizing Variables in k-Means Clustering''
Abs:
Several standardization methods are
investigated in conjunction with the 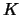 -means algorithm under
various conditions. We find that traditional standardization
methods (i.e.,
-means algorithm under
various conditions. We find that traditional standardization
methods (i.e., 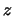 -scores) are inferior to alternative
standardization methods. Future suggestions concerning the
combination of standardization and variable selection are
considered.
-scores) are inferior to alternative
standardization methods. Future suggestions concerning the
combination of standardization and variable selection are
considered.
Akinobu Takeuchi, Jissen Women's University, Takayuki Saito,
Tokyo Institute of Technology, and Hiroshi Yadohisa, Kagoshima
University, ``Extension of Average Linkage Clustering to Asymmetric
Data''
Abs:
TBA
Basavanneppa Tallur, University of Rennes 1,
``Hierarchical Clustering of Binary Attribute Data Based on Correlation
with Application to Bioinformatics''
Abs:
Cluster analysis is among the most useful data analysis tools in all fields of
scientific research. There exist a great number of methods and software tools
for performing cluster analysis and, a typical data set is contained
in a data table whose
rows represent 'observations' (or 'individuals') and columns, the 'variables'
(or 'attributes'). The following three elements are of crucial
importance in building
a hierarchical clustering method:
1. a suitable mathematical representation of data that takes into
account the nature
(or type) of the attributes;
2. a measure of distance (or similarity) between observations and/or attributes
depending on whether one intends to cluster the set of observations,
attributes,
or both;
3. the cluster joining criterion.
The binary attributes are naturally present in many application
dommains (and almost all
other types of data may be easily transformed into binary attributes).
The literature is rich with hundreds of similarity measures for such
data but most of them
are 'biased' and unfit to be used directly in clustering
algorithms. We propose
a similarity index for this type of data that has been derived
starting from the
the 'observation profiles' representation of data akin to the one used
in correspondence
analysis, and is based on the concept of correlation between variables.
The cluster joining criterion is also coherent with data
representation and this combination
has led to a very elegant and efficient clustering method. This method
has been tested on
various real world data and compared with some classical methods. We
will describe one of
our latest applications in bioinformatics.
Tao Tao and ChengXiang Zhai, University of Illinois at
Urbana-Champaign, ``A Mixture Clustering Model for Pseudo Feedback in
Information Retrieval''
Abs:
In this paper, we present a
new mixture model for performing pseudo feedback for information
retrieval. The basic idea is to treat the words in each feedback
document as observations from a two-component multinomial mixture
model, where one component is a topic model anchored to the
original query model through a prior and the other is fixed to
some background word distribution. We estimate the topic model
based on the feedback documents and use it as a new query model
for ranking documents.
Michel Tenenhaus, HEC Business School,
``PLS Path Modeling for Multiple Table Analysis''
Abs:
A situation where 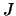 blocks of variables are observed on the same set of individuals is
considered in this paper.
A factor analysis logic is applied to tables instead of individuals.
The latent variables of each block should explain their own block well
and at the same time the latent variables of the same rank should be
as positively correlated as possible.
In the first part of the paper we describe the hierarchical PLS
path model and review the fact that it allows one to recover the
usual multiple table analysis methods.
In the second part we suppose that the number of latent variables
can be different from one block to another and that these latent
variables are orthogonal.
PLS regression and PLS path modeling are used for this situation.
This approach is illustrated by an example from sensory analysis.
blocks of variables are observed on the same set of individuals is
considered in this paper.
A factor analysis logic is applied to tables instead of individuals.
The latent variables of each block should explain their own block well
and at the same time the latent variables of the same rank should be
as positively correlated as possible.
In the first part of the paper we describe the hierarchical PLS
path model and review the fact that it allows one to recover the
usual multiple table analysis methods.
In the second part we suppose that the number of latent variables
can be different from one block to another and that these latent
variables are orthogonal.
PLS regression and PLS path modeling are used for this situation.
This approach is illustrated by an example from sensory analysis.
F. Goupil-Testu, M. Touati, I. Wagne, Université of
Paris IX-Dauphine, A. Pelc, CCMSA, and E. Diday, Université of
Paris IX-Dauphine, ``Analysis of Drug Dispensing with Symbolic
Methods''
Abs:
This work is a study of the dispensing of drugs to people over 70
years old, affiliated to the Caisse Centrale de la Mutualite Sociale
Agricole (CCMSA), the head of french social security organization
(MSA) covering the agricultural area.
The CCMSA stores yearly about 130 million records of payment
operations in its data warehouse. These records accurately reflect the
operations related to the 8.7 billion euros paid to the affiliates,
for Sickness - Maternity - Work injuries. The aim is to improve the
risk management. The basic idea is to aggregate the initial elementary
data into more complex data , called "concepts" modeled by "symbolic
objects", and apply to these new data types an extension of the
classical data analysis methods called "Symbolic Data Analysis". There
has been a drastic reduction of the data, with a minimal information
loss, since the individual data relating to the people belonging to
the concept have been replaced by intervals or probability
distributions, also allowing the data handling to keep
confidential. For now, the study only takes a limited data sample,
coming from the drug payments to the MSA affiliates of the Morbihan
department aged over 70, for the fourth quarter of year 2002. So, for
the referenced period and area, there are 315724 refunding lines,
coming from 81861 prescriptions done by 2249 doctors, for 19541
insured. For instance, among the "high consumers" we find the insured
in ALD (long term payment exemption for severe illness), mainly women,
who are higher consumers of fully refunded drugs than those of the
"low consumers" class. More generally, the advantage of working on
concepts is that we reduce the data and we find risk categories
keeping confidentiality.
Javier Trejos, Alex Murillo, and Eduardo Piza, University of
Costa Rica, ``Clustering by Ant
Colony Optimization''
Abs:
We use the heuristic known as ant colony optimization in the
partitioning problem for improving solutions of k-means method
(McQueen (1967)).
Each ant in the algorithm is associated with a partition, which is modified by
the principles of the heuristic;
that is, by the random selection of an element,
and the assignment of another element which is chosen according
to a probability that depends on the pheromone trail (related to
the overall criterion: the maximization of the between-classes variance),
and a local criterion (the distance between objects).
The pheromone trail is reinforced for those objects that belong to the
same class.
We present some preliminary results, compared to results of other techniques,
such as simulated annealing, genetic algorithms, tabu search, and k-means.
Our results are as good as the best of the above methods.
Heather Turner, Trevor Bailey, and Wojtek Krzanowski, University of
Exeter, ``The Plaid Model: Some Enhancements and Extensions''
Abs:
This talk describes a range of improvements and extensions to the
plaid model, a two-way clustering method developed by Lazzeroni
and Owen (2002) for analysing gene expression data. The model has
a probabilistic ANOVA-type structure, in which
the expression level 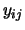 of the
of the 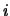 th gene in the
th gene in the 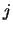 th sample
is given by
th sample
is given by
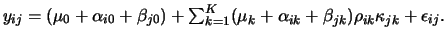 Here
Here 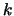 indexes each of the biclusters,
indexes each of the biclusters, 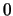 indexes the
background,
indexes the
background, 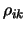 and
and 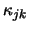 are indicators that show presence or
absence of gene and sample in bicluster , and
are indicators that show presence or
absence of gene and sample in bicluster , and
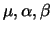 are mean, gene and sample effects respectively.
In the first part of the talk we briefly survey biclustering of
microarray data, introduce the plaid model, outline the original
method of fitting it, and describe an alternative approach based on
the SINDCLUS algorithm (Chaturvedi and Carroll, 1994).
The alternative method shows improved efficiency when tested against
the original method on simulated microarray data.
In the second part of the talk we then consider several modifications to
the model itself. First, grouping information can be incorporated to allow
partial supervision of the clustering process, favouring more
interpretable clusters. Second, extra parameters can be added to the model
when each gene/sample combination contains repeated measurements, usually
over time. This enables three-way data to be analysed, avoiding the
loss of information produced by
collapsing complex datasets. Computing implications are
discussed, and real data examples are used to illustrate all the
proposed extensions.
are mean, gene and sample effects respectively.
In the first part of the talk we briefly survey biclustering of
microarray data, introduce the plaid model, outline the original
method of fitting it, and describe an alternative approach based on
the SINDCLUS algorithm (Chaturvedi and Carroll, 1994).
The alternative method shows improved efficiency when tested against
the original method on simulated microarray data.
In the second part of the talk we then consider several modifications to
the model itself. First, grouping information can be incorporated to allow
partial supervision of the clustering process, favouring more
interpretable clusters. Second, extra parameters can be added to the model
when each gene/sample combination contains repeated measurements, usually
over time. This enables three-way data to be analysed, avoiding the
loss of information produced by
collapsing complex datasets. Computing implications are
discussed, and real data examples are used to illustrate all the
proposed extensions.
Iven van Mechelen, Catholic University of Leuven, ``Three-Way
Classification Models: An Overview''
Abs:
In this paper, I will present a structured overview of models and
data-analytic methods for three-way three-mode data that imply a
clustering of one or more modes of the data. This overview was
inspired by the pioneering work of Hartigan (1972, 1975), and links up
with a recent comprehensive taxonomy of the two-mode clustering domain
(Van Mechelen, Bock, & De Boeck, in press). Key structuring
principles of the overview include: (1) the number of modes that are
simultaneously clustered -one, two or all three- (with for the
possibly nonclustered mode(s) the option of an additional simultaneous
dimensional reduction), (2) whether the data clusterings implied by
the methods are partitions, nested hierarchies or overlapping
clusterings, and (3) whether the methods are based on a deterministic
or on a stochastic (mixture or fixed-classification) model. Existing
clustering methods for three-way three-mode data (and their
interrelations) will be located in the overview, including three-way
tandem analysis, three-way mixture modeling, weighted ultrametric
trees, three-way GENNCLUS, three-mode partitioning, three-mode
hierarchical cluster analysis, three-mode overlapping CANDCLUS, and
three-way hierarchical classes modeling. In addition, several still
to be developed methods as implied by the taxonomy will be pointed at
as well.
Bart Jan van Os, Leiden University,
``Globally Optimal Partitioning by Dynamic Programing''
Abs:
Nonexhaustive partitioning problems may arise in at least two psychometric
areas. First, nonexhaustive clustering proposes to cluster only a subset of
the objects under study. Such approaches are most popular in
pattern recognition (Theodoridis and Koutroumbas, 1998) and bioinformatics
(de Bruin, 1998), where they are combined with fast sequential algorithms,
but they may also be used in other areas. Objectives for nonexhaustive
clustering might be the need of a few small prototypical clusters, or the
avoidance of outlier influence on the clusters solution and it's quality
assessment.
In this talk a globally optimal approach to (small) non-exhaustive
partitioning problems will
be pursued. In such an approach, the objective is to maximize the sum of
some (homogeneity) function of the individual clusters/tests, without the
necessity to include all objects/items in the solution. Special care in
formulating this objective function is to be taken to avoid including to
few or to many objects/items. To solve this problem globally optimal, two
approaches to an exact Dynamic Programming algorithm are presented. The
algorithm will be applied to a dataset involving employement in nine
different industries in 22 selected European countries during the Cold War.
Mark Vangel, Massachusetts General Hospital and Harvard University,
``Combining Functional MRI Data on Multiple Subjects''
Abs:
Worsley et al. (2002) propose a practical approach to
multiple-subject functional MRI data analyses which uses the EM
algorithm to estimate the between-subject variance component at each
voxel. The main result of this article is a demonstration that the
much more efficient Newton-Raphson algorithm can be reliably used for
these calculations. This result follows from an extension of a simple
algorithm proposed by Mandel and Paule (1970) for the one-way
unbalanced ANOVA model, two variants of which have been shown to be
equivalent to modified ML and REML, in which the ``modification'' is
that the within-subject variances as treated as known.
Vladimir Vapnik, AT&T, Title TBA
Maurizio Vichi and Roberto Rocci, University ``La
Sapienza'' and University ``Tor Vergata'' of Rome, ``Multimode
Clustering''
Abs:
In this paper, new methodologies for multi-mode clustering of a two-
(three-) way data set are proposed. The two- (three-) mode clustering
model, here adopted, is as a collection of disjoint object and
variable clusters (object, variable and occasion clusters),
identifying a data matrix (array) which is split into disjoint blocks
of sub-matrices (sub-arrays), where entries within blocks change only
for a random residual. When the multimode clustering degenerates into
the clustering of the objects only, and the model is estimated with a
least-squares loss function, the methodology reduces to the well-known
k-means algorithm (Mac Queen 1967). In this paper, the two- (three-)
mode clustering model is estimated under the model-free assumptions in
a least-squares context, by using an new algorithm, which is named
double (triple) k-means.
First, we show how to estimate the two- (three-) mode clustering model
by using sequential procedures based on the k-means algorithm. We
observe that these procedures generally give non optimal estimations
of the two- (three-) mode model. Efficient alternating least-squares
(ALS) algorithms are then proposed. Hence, the sequential procedures
will be used as useful starting point for the ALS algorithms.
A simulation study to test the performances of the algorithms will
also be presented. It is well-known that k-means algorithm frequently
stops to local minima solutions. Therefore, we will test how this
problem is severe in our algorithms. In the case clusters of objects
and variables are well- separated, the problem is solved -for data
sets with dimension (1000 objects ´ 400 variables)- by using 15 random
initial solutions and by retaining among these the best result.
When the error level added to the model is very high the generated
solution is not any more formed by well-separated clusters. In fact,
the best solution given by the algorithm was always better than that
generated, when the number of initial random starts was fixed equal to
30.
It is interesting to note that double and triple k-means maintain the
feature of the k-means to be fast algorithms applicable also to very
large data sets.
Kiri Wagstaff, Jet Propulsion Laboratory,
``Clustering with Missing Values: No Imputation Required''
Abs:
Clustering algorithms can identify groups in large data
sets, such as star catalogs and hyperspectral images. In general,
clustering methods cannot analyze items that have missing data values.
Common solutions
either fill in the missing values (imputation) or ignore the missing
data (marginalization). Imputed values are treated as being just as
reliable as the observed data, but they are only as good as the
assumptions used to create them.
In contrast, we present a method for encoding partially observed
features as a set of supplemental soft constraints
and introduce the KSC algorithm, which incorporates constraints
into the clustering process.
In experiments on artificial data and data from the Sloan
Digital Sky Survey, we show that soft constraints are an
effective way to
enable clustering with missing values.
Guenther Walther, R. Tibshirani, D. Botstein, and P.
Brown, Stanford University, ``Cluster Validation by
Prediction Length''
Abs:
We propose a new quantity for assessing the number of groups or clusters in a
dataset.
The key idea is to view clustering as a supervised classification
problem, in which we must also estimate the ``true'' class labels.
The resulting ``prediction strength'' measure assesses how many groups
can be predicted from the data, and how well. In the process, we
develop novel notions of bias and variance for unlabelled
data.
Prediction strength performs well in simulation studies,
and we apply it to clusters of breast cancer samples from
a DNA microarray study. Finally, some consistency properties of the method
are established.
Leland Wilkinson, SPSS, Inc., ``Streaming Data in Multiple
Windows''
Abs:
Norton and Wilkinson (2001) introduced a system, called Dancer, for graphing
real-time data streams. This talk covers an extension of this system to
handle graphing of multiple streams simultaneously in multiple windows. We
discuss data fusion mechanisms and rendering models which enable
display of multiple streams in real time (up to 10,000 events per second).
Graham Wills, SPSS, Inc., ``Transformations of Graphs''
Abs:
The Grammar of Graphics (1999) presents examples of ordinary charts that are
embedded in non-rectangular coordinate systems. In many of these examples,
structures that are difficult to discern in rectangular coordinates are
easier to detect in alternative coordinates. This talk extends the idea of
graphing in non-rectangular coordinates to graphing with coordinate
transformation chains. We discuss the mechanisms for composing coordinates
in a graphics system and present examples that illustrate the usefulness of
these methods.
David Wishart, University of St. Andrews,
``Classification of Single Malt Whiskies
by Flavour''
Abs:
We describe the cardinal flavours that are found in single malt
whiskies, and explain how the production and maturation processes
influence these flavours. To simplify the comparison of malt whiskies,
a standardized profile of 12 cardinal flavours was developed from
around 1000 tasting notes and over 500 whisky terms. The principal
malt whiskies from all the Scottish distilleries were then profiled
and classified by flavour (Wishart, 2000).
This helps answer questions like - (1) My store offers a bewildering
selection of malt whiskies, so what should I buy? (2) Dad drinks
Macallan but I want to give him another malt that's similar in flavour
which he will also enjoy? (3) Can you suggest six malts for my cabinet
that illustrate the range of single malt whiskies?
Whisky Classified: Choosing Single Malts by Flavour is the first book
to classify single malt whiskies by flavour. It does not rate whiskies
by marks-out-of-ten for quality, or describe them by regional
styles. It is a consumer-friendly guide that takes the confusion and
guesswork out of whisky-buying, and aims to help the novice or
present-buyer make the right purchase of Scotland's national drink. It
is also an interesting application of classification methodology for a
non-technical readership, and arguably the most widely sold book
derived from a product segmentation.
This paper extends the previous work by developing TypeAnalyst, a
retailing aid to identify the appropriate cluster and nearest
neighbours of new whisky expressions. The presentation concludes with
a tutored tasting sponsored by Aberfeldy 12yo, Aberlour 10yo, Ardbeg
10yo, Auchentoshan 10yo, Balblair 16yo, Balvenie 12yo, Balvenie
DoubleWood 12yo, Benromach 18yo, Bowmore 12yo, Bruichladdich 10yo,
Bunnahabhain 10yo, Dalmore 12yo, Deanston 10yo, Edradour 10yo, Glen
Deveron 10yo, Glenfarclas 12yo, Glenfiddich 12yo, Glen Garioch 10yo,
Glengoyne 10yo, Glenlivet 12yo, Glenmorangie 12yo, Glenmorangie
Madeira Finish 12yo, Glenmorangie Sherry Finish 12yo, Glen Moray 10yo,
Glenrothes 1989, Highland Park 18yo, Isle of Jura Superstition,
Macallan Cask Strength, Laphroaig 10yo, Old Pulteney 12yo, Speyburn
10yo, Springbank 10yo, Strathisla 12yo, Tamdhu 10yo and Tobermoray
10yo.
Wenshang Wu, the University of Illinois at Urbana-Champaign,
Clement Yu, University of Illinois at Chicago, and Weiyi Meng, State
University of New York at Binghamton,
``Database Selection for Longer Queries''
Abs:
In this paper, we propose a new method
to construct database representatives and to decide which databases to
select for a given query when the query may be long.
One critical difference from earlier approaches is that
the dependencies of words in documents are captured in the
database representatives.
Usually, the dependencies are limited to phrases,
especially noun phrases.
S. Stanley Young, National Institute of Statistical Sciences, ``The
Use of
Metabolomic Data to Predict Disease Status''
Abs:
Metabolomics is the new `omics' science that concerns
biochemistry.
A metabolomic dataset includes quantitative measurements of all
small molecules, known as metabolites, in a biological sample. These
datasets are rich in information regarding dynamic metabolic (or
biochemical) networks that are unattainable using classical methods
and have great potential, conjointly with other omic data, in
understanding the functionality of genes. Herein, we explore a complex
metabolomic dataset with the goal of using the metabolic information
to correctly classify individuals into different
classes. Unfortunately, these datasets incur many statistical
challenges: the number of samples is less than the number of
metabolites; there is missing data and non-normal data; and there are high
correlations among the metabolites. Thus, we investigate the use of
robust singular value decomposition, rSVD, and recursive partitioning
to understand this metabolomic data set. The dataset consists of 63
samples, in which we know the status of the individuals (disease or
normal and for the diseased individuals, if they are on drug or
not). Clustering using only the metabolite data is only modestly
successful. Using distances generated from multiple tree recursive
partitioning is more successful.
Bei Yu, University of Illinois at
Urbana-Champaign,
``Discriminating Writing Styles Between Native and Non-Native English
Writers''
Abs:
Identifying the differences in academic writing between native and
non-native speakers is a research problem in second language
acquisition and contrastive linguistics. This ongoing project is a
computational analysis of the collective writing style differences
between the writing of Chinese and English speakers.
To formalize this problem as a classification task, research articles
written by English and Chinese speakers are represented as vectors of
the following normalized style features: common word sequences
frequencies, parts-of-speech frequencies and other general style
markers such as word length and sentence length, etc. The space of
features is then reduced and transformed with the goal of predicting
whether the author is English or Chinese speaker. Three classification
algorithms are proposed for testing and comparison: decision tree,
naive Bayesian and discriminant analysis. Aims include an assessment
of the discriminatory power of the features.
Helen Zhang, North Carolina State University, ``Unified Multiclass
Proximal Support Vector Machines''
Abs:
TBA
Up: abstracts
Previous: Abstracts E-N